life's a struggle.
Intelligence without ambition is a bird without wings.
2014-12-08
2014-12-08
概念
str object和unicode object是两种不同的类型
字符串
字符组成的序列
而字符是经过编码的,常见的编码如ASCII,GB2312,UTF-8等等
词法
引号括起来的字符序列
unicode字符串
unicode码元序列
在python里,16-bit的unicode,对应的是ucs2编码。32-bit对应的是ucs4编码
通过sys.maxunicode可以查看当前Python的unicode编码
词法
引号括起来的字符序列,前面加u,如u'Hello world'
参考
2014-12-08
字符编码
将字符集中的字符用另一集合中的对象来表示,以便存储或传输。
从数学角度上说,就是一种映射,更准确地说,是一种单射函数,具有唯一确定性,但不存在多个字符映射为同一个码元!
常见的编码方式有,ASCII,摩尔斯电码等。
参考:
字符
一个基本信息单位,如字母,数字,标点符号,控制字符等。
参考:
字符集
字符的集合
代码页
字符编码的别名
参考:
码位
字符在编码表中的值,一般为非负整数。
注:
- 并不直接对应在计算机中的表达,如一个字符在unicode字符集中的码位,具体怎么表示,取决于编码方式(UTF-8,UTF-16…)
码元
已编码的字符集中占用最小的比特数,如UTF-8为8,UTF-16为16。
字形
一个可以辨认的抽象的图形符号,它不依赖于任何特定的设计,即字符的构成形式
字体
参考
2014-12-08
unicode内部编码实现
python2 UCS2(编译默认,–enable-unicode=ucs2)
>>> sys.maxunicode 65535python3 UCS4(编译默认,–enable-unicode=ucs4)
>>> sys.maxunicode 1114111
相关数据类型
字节序列(bytes)
一串由0到255之间的数字组成的序列叫做bytes对象
用来存储经过某种编码方式(如
UTF-8)的unicode字符串转换为字符串时,需要知道该
bytes的编码
字符串(string)
字符是一种抽象
一个不可变(immutable)的Unicode编码的字符序列叫做string
存储对应的UNICODE编码值
python源文件编码方式
python2 默认编码为ASCII,若为其他编码,需要在文件头注释说明(
coding: XXX)python3 默认UTF-8
编码转换(str <=> bytes)
python3
string => bytes
a_string = '深入 Python' by = a_string.encode('utf-8') len(by) by = a_string.encode('gb18030') len(by)bytes => string
a_string = '深入 Python' by = a_string.encode('utf-8') by.decode('utf-8')
参考:
- http://stackoverflow.com/questions/1446347/how-to-find-out-if-python-is-compiled-with-ucs-2-or-ucs-4
获取系统编码参数
系统的缺省编码(一般就是ascii):sys.getdefaultencoding()
系统当前的编码:locale.getdefaultlocale()
系统代码中临时被更改的编码(通过locale.setlocale(locale.LC_ALL,“zh_CN.UTF-8″)):locale.getlocale()
文件系统的编码:sys.getfilesystemencoding()
终端的输入编码:sys.stdin.encoding
终端的输出编码:sys.stdout.encoding
文件编码与字符串编码
字符床常量编码取决于文件编码
默认编码为ASCII
文件头显式指定编码,需要文件本身编码与该声明编码一致
# Coding: utf-8
定义UNICODE字符串,在字符床常量前加u
判断字符串编码
type(str)isinstance()
1 | print 'default encoding: ' , sys.getdefaultencoding() |
常见问题
SyntaxError: Non-ASCII character '\xe4' in file XXX
- 原因
文件编码不是ASCII编码,但文件开头未指定文件编码
- 解决
在文件开头指定文件本身编码即可.(文件最好采用utf-8编码)
参考
2014-12-08
2014-12-08
情景描述
路由器下接多台交换机,不同交换机所属VLAN不同,1台PC被插到非目标交换机当中。
问题
如何找出PC在交换机中的端口?
解决
记录当前网络端口状态
采用手机拍照,拍取当前PC所属交换机

拔出PC机箱后网线
与拍照比对
拍照时亮的端口,断开PC后,不亮的端口即为PC所插交换机端口
2014-12-08
输入网络打印机路径(通过IP访问)
\\xxx.xxx.xxx.xxx安装打印机驱动
双击打印机图标
2014-12-06
右击【项目根目录】
点击菜单
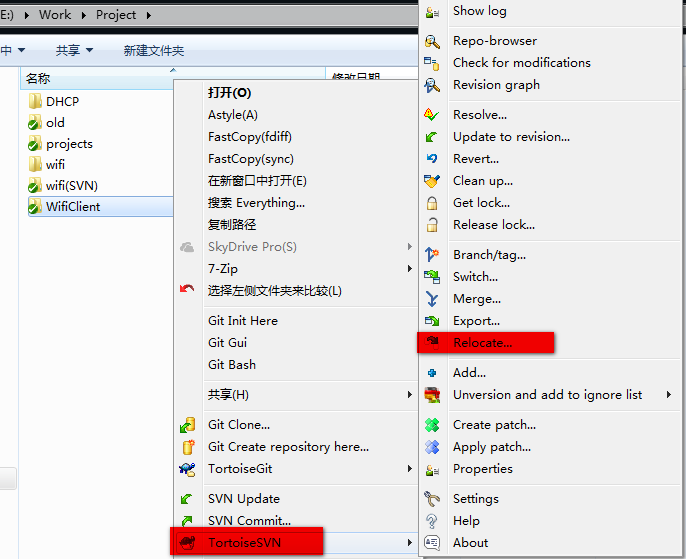
2014-12-05
2014-12-05
代码
- 变量为字符串类型(优雅的方式)
1 | if not string: |
- 变量类型不确定
1 | if string == '': |